Есть разные способы резервного копирования на Google диск, самый простой на мой взгляд это использовать Duplicati, единственный минусом которого является пожалуй то, что архив созданный Duplicati можно распаковать только Duplicati, так как он создает архивы по какому то своему алгоритму и простая распаковка ничего не даст правильного расположения и названия файлов. В данной статье пойдет речь о том, как делать архивирование на Google диск c помощью gdrive3
Программу можно скачать отсюда, настройки со стороны Google описаны тут или тут в картинках, в данной статье не рассматривается эти настройки, предпологается, что программа скачана и помещена по одному из путей PATH, например /usr/local/bin
Открываем терминал и регистрируем программу на гугле
gdrive account addвводим Client ID и Client Secret, программа выдаст Вам ссылку, копируем её и вставляем в браузер, после авторизации браузер выдаст Вам адрес начинающийся с 127.0.0.1:8085..., копируем полностью адрес из строки адреса браузера, открываем новую вкладку терминала (старую не закрываем) и вводим curl и скопированный адрес, должно начинаться так:
curl 127.0.0.1:8085...в первой вкладке терминала должна программа завершить свою работу, это значит аккаунт зарегистрирован
Есть много способов сделать архивирование файлов и базы данных, я приведу пример архивирования баз данных mysql и файлов, а затем мы архивы будем копировать на гугл диск
Архивирование баз данных.
заходим в терминал по ssh и создаем файл
nano /root/script/dbbackupсо следующим содержимым:
#!/bin/bash
USER="dbuser"
PASSWORD="dbpassword"
OUTPUT="/root/gdbackup/db_backup" #директория для хранения резервных копий
databases=`docker exec mariadb mariadb --user=$USER --password=$PASSWORD -e "SHOW DATABASES;" | tr -d "| " | grep -v Database`
for db in $databases; do
if [[ "$db" != "information_schema" ]] && [[ "$db" != _* ]] ; then
echo "Dumping database: $db"
mkdir -p $OUTPUT/$db/$1
docker exec mariadb mariadb-dump -u root -plordoftherings $db > $OUTPUT/$db/$1/`date +%Y%m%d`.$db.sql
if ! [ -d $OUTPUT/$db/$1/ ]; then
echo 'No directory'
mkdir $OUTPUT/$db/$1
fi
if ! [ -f $OUTPUT/$db/$1/`date +%Y%m%d`.$db.sql.gz ]; then
echo 'No file'
gzip $OUTPUT/$db/$1/`date +%Y%m%d`.$db.sql
else
rm $OUTPUT/$db/$1/`date +%Y%m%d`.$db.sql
fi
find $OUTPUT/$db/day -type f -mtime +8 -delete
find $OUTPUT/$db/week -type f -mtime +34 -delete
fi
doneUSER, PASSWORD и OUTPUT вставьте свои, папки по пути OUTPUT должны быть созданы
у меня mariadb стоит в Docker контейнере, по этому 5-я строка запроса к базе данных имеет такой вид, если у Вас не в Docker контейнере то необходимо во всех строках (5-я и 10-я) удалить «docker exec mariadb «,
скрипт принимает параметр и работает следующим образом:
создает папку с именем базы данных, в папке создает папку с переданным параметром и туда создает архив соответствующей базы данных, после чего удаляет файлы в папке day старше 8-и дней и в папке week старше 34 дней, предпологается, что в эти папки будут копироваться файлы соответственно ежедневно и еженедельно, для автоматического копирования добавляем в crontab:
0 0 * * * /root/script/dbbackup /day
0 0 * * 0 /root/script/dbbackup /week
0 0 1 * * /root/script/dbbackup /monthсоответственно архивы будут создаваться каждый день/неделю и месяц и помещаться в соответствующие папки
Архивирование папок
В архивировании папок нет ничего сложного, можно создавать каждый раз полный архив папки и потом копировать его на Google диск, но в данном примере будет создаваться первый раз весь архив папки и при последующем запуске скрипта будет создаваться архив только с новыми и измененными файлами.
создаем файл:
nano /root/script/backupсо следующим содержимым
#!/bin/sh
BACKUP=/root/gdbackup/backup # путь к дирректории с бэкапами
FOLDER=/root/folder # папка для архивации
DAY=$(date +%d) #Получаем номер дня
MON=$(date +%m) #Получаем номер месяца
DATE=$(date +%Y%m%d)
mkdir -p $BACKUP
if ! [ -f $BACKUP/backup.snar ]; then
echo 'No file'
NU="_NEW"
else
NU="_ADD"
fi
# Создаем архив
tar --create \
--gzip \
--file=$BACKUP/$DATE$NU.tgz \
--ignore-failed-read \
--listed-incremental=$BACKUP/backup.snar \
$FOLDERи добавляем в crontab запуск скрипта с необходимой периодичностью, создаваться будут такие файлы:
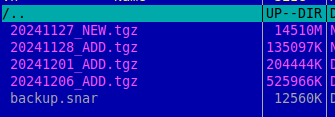
файл с окончанием NEW — это полный начальный архив, файлы с окончанием ADD это архивы в которых новые или измененные файлы, backup.snap — это индексный файл в котором информация о добавленных файлах, если его удалить то создастся архив со всеми файлами.
Копирование файлов на Google диск
создаем скрипт для копирования файлов на Google диск
nano /root/script/gdbackupсо следующим содержимым:
#!/bin/bash
BACKUP_DIR="/root/gdbackup" # папка для архива
GD_DIR="gdbackup" # название папки для архивации на Google диске
MTIME=-7 #копировать файлы не старше (-7 - семь дней)
IFS='/' # разделитель пути файлов
BAK_TMP="${BACKUP_DIR##*/}"
find "$BACKUP_DIR" -type f -mtime $MTIME| while read file; do
PATHF=$GD_DIR/${file#*/$BAK_TMP/}
PATHFF=$file
echo ""
echo "Найден файл: $PATHF"
COUNT1=0
COUNT2=0
for part in $PATHF; do
COUNT1=$((COUNT1 + 1))
done
for part in $PATHF; do
COUNT2=$((COUNT2 + 1))
if [ $COUNT2 = $COUNT1 ]; then
#проверяем есть ли файл на диске
FILE_ID=$(gdrive files list --parent "$FOLDER_S" --skip-header | grep "$part" | awk '{print $1}')
if [ -z "$FILE_ID" ]; then
# файла нет, копируем файл на диск
echo "нет файла на гугл диске, копируем файл $PATHFF"
gdrive files upload --parent "$FOLDER_S" "$PATHFF"
else
echo "Файл $part существует, имеет ID: $FILE_ID"
fi
else
#папка
if [ "$COUNT2" -eq 1 ]; then
# первая папка
echo "проверяем есть ли папка $part"
FOLDER_ID=$(gdrive files list --skip-header | grep "$part" | awk '{print $1}')
if [ -z "$FOLDER_ID" ]; then
echo "Папки нет, создаем папку $part"
FOLDER_S=$(gdrive files mkdir $part | awk '{print $6}')
echo "Папка $part создана, имеет ID: $FOLDER_S"
else
echo "корневая папка $part есть, имеет ID: $FOLDER_ID"
FOLDER_S=$FOLDER_ID
fi
else
# не первая папка
if [ -z "$FOLDER_S" ]; then
echo "НЕТ ИДЕНТИФИКАТОРА!!!!!!!"
else
FOLDER_ID=$(gdrive files list --parent "$FOLDER_S" --skip-header | grep "$part" | awk '{print $1}')
fi
if [ -z "$FOLDER_ID" ]; then
echo "папки не существует, создаем вложенную папку $part в папке с ID $FOLDER_S"
FOLDER_ID=$(gdrive files mkdir --parent "$FOLDER_S" $part | awk '{print $6}')
echo "Папка $part создана в папке "$FOLDER_S", имеет ID: $FOLDER_ID"
FOLDER_S=$FOLDER_ID
else
echo "папка $part есть, имеет ID: $FOLDER_ID"
FOLDER_S=$FOLDER_ID
fi
fi
fi
done
doneсоответственно меняем на свои:
BACKUP_DIR="/root/gdbackup" # папка для архива
GD_DIR="gdbackup" # название папки для архивации на Google диске
MTIME=-7 #копировать файлы не старше (-7 - семь дней)для первого запуска скрипта если у Вас уже сделана система архивирования и архивов уже поднакопилось можно сделать MTIME больше, а потом изменить обратно на количество дней кратно периодичности запуска, у меня запуск скрипта раз в неделю.
скрипт проверяет есть ли папка, если нет то создает и проверяет есть ли файл, если нету то копирует.
Старые файлы которые удалены скрипт с Google диска не удаляет.